Selective Brain Damage: Measuring the Disparate Impact of Model Compression
Sara Hooker, Aaron Courville, Yann Dauphin, Andrea Frome
What is lost when we prune deep neural networks?
Between infancy and adulthood, the number of synapses in our brain first multiply and then fall.
Synaptic pruning improves efficiency by removing redundant neurons and strengthening synaptic connections
that are most useful for the environment.
Despite losing 50 % of all synapses between age two and ten, the brain continues to function .
The phrase "use it or lose it" is frequently used to describe the environmental influence of the learning process
on synaptic pruning,
however there is little scientific
consensus on what exactly is lost .
In 1990, a popular paper was published titled Optimal Brain Damage.
The paper was amongst the first to propose that deep neural networks could be pruned of "excess capacity" in a similar way
to our biological synaptic pruning. In deep neural networks, weights are pruned or removed by
from the network by setting the value to zero.
Today there are many possible pruning methods to chose from, and pruned models likely drive many of the algorithms on your phone.
At face value, pruning does appear to promise you can can (almost) have it all.
State of art pruning methods remove the
majority of the weights with minimal degradation to top-1 accuracy.
These newly slimmed down networks require less memory, energy consumption
and are faster at producing predictions.
All these attributes make pruned models ideal for deploying deep neural networks to resource constrained environments.
Synaptic pruning removes redundant neurons and strengthens connections that are most useful for the environment. (Figure courtesy of Seeman, 1999)
However, the ability to prune networks with seemingly so little degradation to generalization performance is puzzling. The cost
to top-1 accuracy appears minimal
if it is spread uniformally across all classes, but what if the cost is
concentrated in only a few classes?
Are certain types of examples or classes disproportionately impacted by
pruning?
An understanding of these trade-offs is critical when deep neural networks are used for sensitive tasks such
as hiring , health care diagnostics or self-driving cars . For these tasks, the introduction of pruning may be at odds with fairness objectives
to avoid disparate treatment of protected attributes and/or the need to guarantee a level of recall for certain classes .
Pruning is already commonly used in these domains, often driven by the resource constraints of deploying models to mobile phone or embedded devices .
In this work, we propose a formal framework to identify the classes and images where there is a high level of disagreement or difference in
generalization performance between pruned and non-pruned models. We find that certain examples, which we term pruning identified exemplars (PIEs),
and classes are systematically more impacted by the introduction of sparsity.
The primary findings of our work can be summarized as follows:
1. Pruning would be better described as "selective brain damage." Pruning has a non-uniform impact across classes; a fraction of classes are disproportionately and systematically impacted by the introduction of sparsity.
2. The examples most impacted by pruning, which we term Pruning Identified Exemplars (PIEs), are more challenging for both pruned and non-pruned models to classify.
3. Pruning significantly reduces robustness to image corruptions and natural adversarial images.
PIE: Pruning Identified Exemplars
PIEs are images where the most frequent prediction differs between a population of independently trained pruned and non-pruned models. We focus on open source research datasets such as ImageNet and find that PIE images are more challenging for both pruned and non-pruned models.
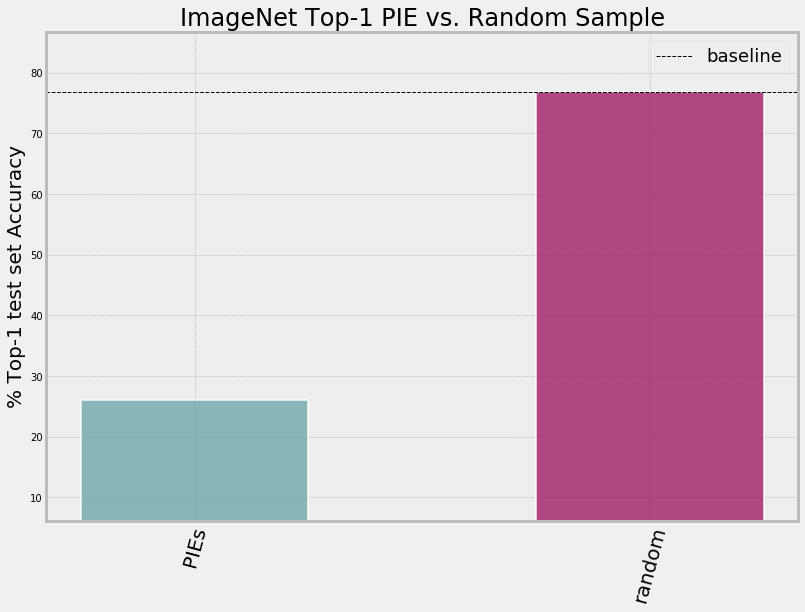
Restricting the test-set to a random sample of PIE images sharply degrades top-1 accuracy.
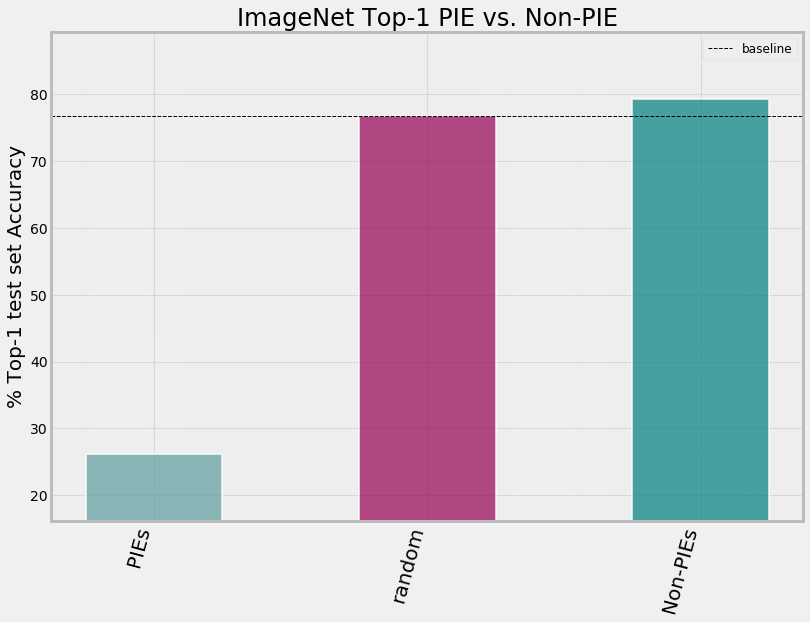
Removing PIEs from the test-set improves top-1 accuracy for both pruned and non-pruned models.
PIE images are more challenging for both pruned and non-pruned models to classify.
Pruning appears to cause deep neural networks to "forget" the examples where there is already a high level of predictive uncertainty.
Go ahead and click on the buttons below to view a sample of ImageNet PIEs in each category.
The labels below each image are: 1) true ground truth ImageNet label, 2) baseline non-pruned
modal prediction, 3) most frequent prediction from a population of pruned ResNet-50 models.
abstract exemplars:a sample of PIEs where the class object is in an abstract form, such as a painting, drawing or rendering
using a different material.
fine grained: a sample of PIEs where the image depicts an object that is semantically close to
various other classes present the data set (e.g.,
rock crab and fiddler crab, cuirass and breastplate).
atypical exemplars: a sample of PIEs where the image would be considered by a human to be an unusual
or outlier example from the distribution of images in a given category.
True Label:toilet tissue Non-Pruned:bath towel Pruned: great white shark
To better understand why PIEs are more sensitive to capacity,
we conducted a limited human study (85 participants) and find that PIEs from the ImageNet test set are more likely to be mislabelled,
depict multiple objects or require fine-grained classification.
Over half of all PIE images were classified by human participants as either having an incorrect ground truth label or depicting multiple objects. The over-indexing of poorly structured data hints that
the explosion in number of parameters for single image classification tasks like ImageNet may be solving a
problem that is better addressed in the data cleaning pipeline.
PIEs overindex on data that is poorly structured for a single image classification tasks. For these images, predicting the correct ground truth may be an incomplete measure of generalization ability to unseen data.
For example, a pruned model that predicts suit instead of the true label of groom would still be considered accurate by most humans. The groom is wearing a suit and thus both labels could be acceptable.
However, this prediction would be penalized by measures such as top-1 accuracy.
Click on the buttons below to view a sample of ImageNet PIEs in each category.
The labels below each image are: 1) true ground truth ImageNet label, 2) baseline non-pruned modal prediction, 3) most frequent prediction from a population of pruned ResNet-50 models.
incorrect or inadequate ground truth: a sample of PIEs where the ground truth label for the image is incorrect or there is insufficient information for a human to predict the correct ground truth label.
multiple objects: a sample of PIEs where the image depicts multiple objects, a human may consider several labels to be appropriate predictions (e.g.,
desktop computer consisting of a screen, mouse and monitor, a barber chair in a barber shop,
a wine bottle which is full of red wine).
frequently co-occuring labels: a sample of PIEs where multiple object(s) occur frequently together in the same image.
In certain cases, such as projectile and missile, this is because both labels are acceptable to describe the same object.
On real world datasets, the stakes are often much higher than correctly classifying a paddle or guacamole. For sensitive tasks such as patient risk stratification or medical diagnoses , our results suggest caution should be excercised before deploying pruned models.
PIE provides one tool to become more familiar with the underlying data by surfacing
a far smaller subset of examples the model finds challenging to the human expert. This can be extremely valuable for creating human-in-the-loop decisions,
where certain atypical examples are re-routed for human inspection or to aid interpretability as a case based reasoning tool to explain model behavior.
Inspecting PIE images can help us understand the types of inputs the model finds most challenging. PIE images are far harder for a model to classify. Removing PIE images improves top-1 generalization performance beyond the baseline.
Go ahead and click the buttons below.
The average top-1 accuracy of a ResNet-50 deep neural network is far lower
on a random sample of PIE ImageNet images (green bar) relative to performance on
a random sample of images from the ImageNet test set (pink bar).
Removing PIE images benefits generalization. Top-1 accuracy improves beyond baseline performance when the model is restricted
to a random sample of non-pie ImageNet images (teal).
What class categories are impacted by pruning?
ImageNet has 1000 different class categories, which include both every day objects such as cassette player and more nuanced categories that refer to the texture of an object such as velvet or even person types such as groom.
If the impact of pruning was uniform across all classes, we would expect the model accuracy on each class to shift by the same
number of percentage points as the difference in top-1 accuracy between the pruned and non-pruned model.
This forms our null hypothesis, and we must decide for each class whether
to reject the null hypothesis and accept the alternative -- the
change to class level recall differs from the change to overall accuracy
in a statistically significant way. This amounts to asking -- did the class perform better or worse than expected given the overall change in top-1 accuracy after pruning?
Evaluating whether the difference between a sample of mean-shifted class accuracy from pruned and non-pruned models is
“real” can be thought of as determining whether two data samples are drawn from the same underlying distribution, which is the subject of a large body of goodness of fit literature .
To compare class level performance between pruned and non-pruned models, we use a two-sample, two-tailed,
independent Welch’s t-test . We independently train a population of pruned and non-pruned models and apply the t-test
to determine whether the means of the samples differ significantly.
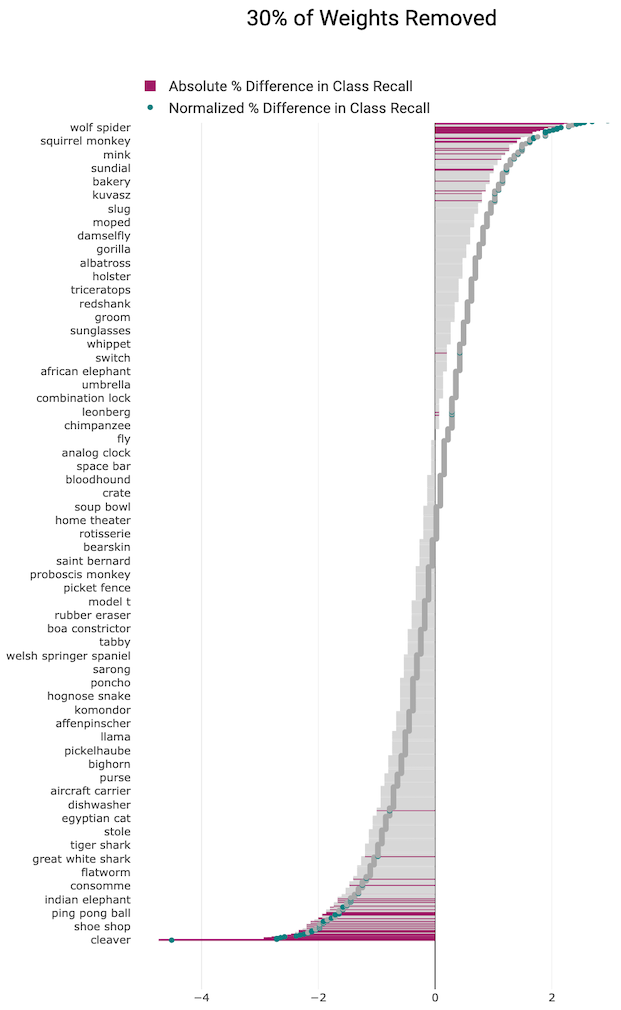
This methodology allows us to identify a subset of classes where model performance either remains relatively robust to the loss of model weights or is overly sensitive to the reduction in capacity.
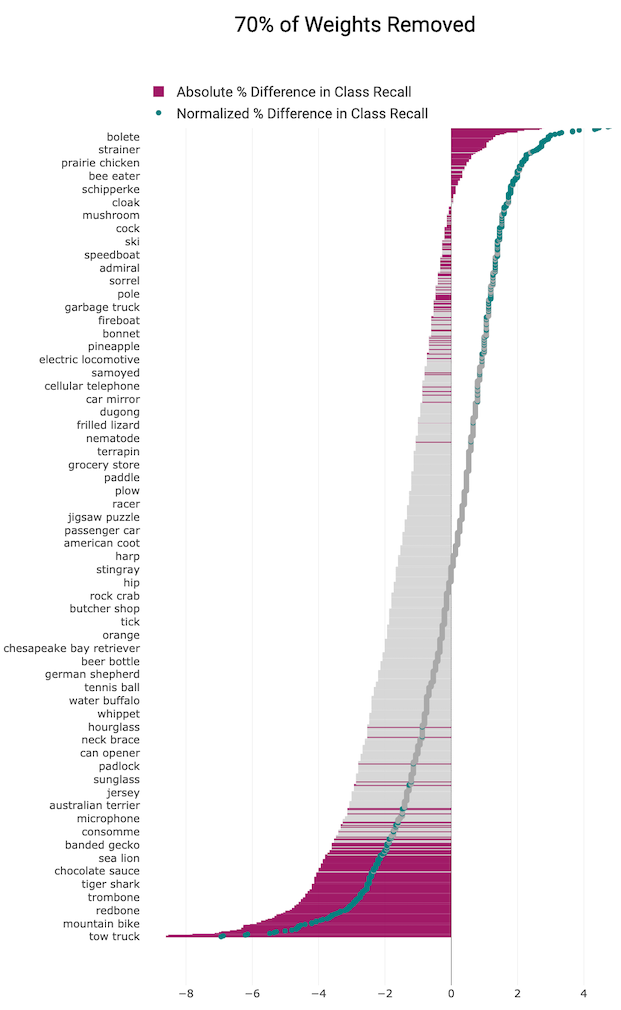
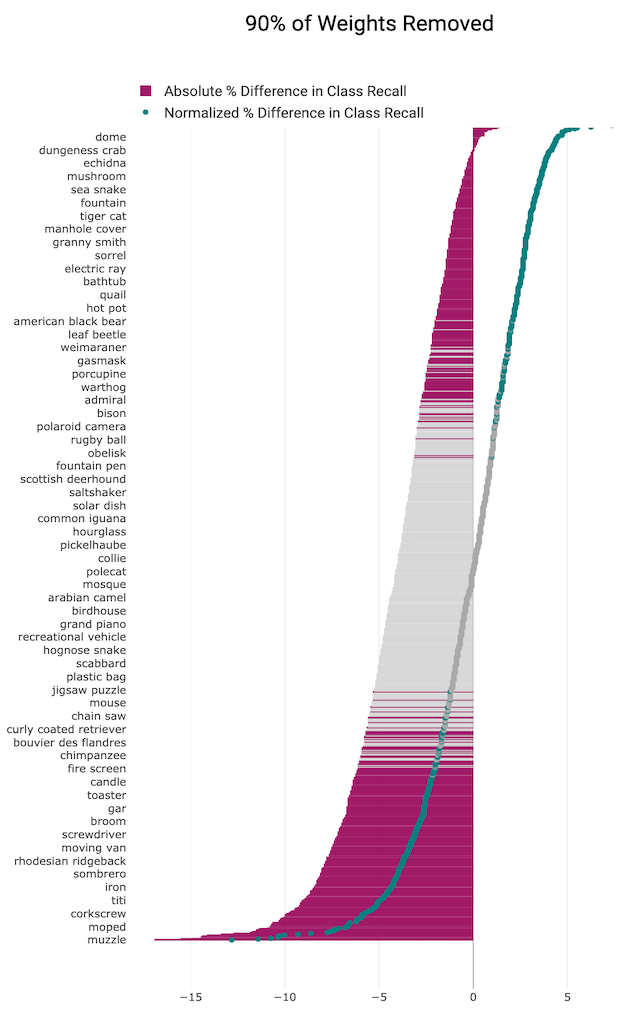
We independently train a population of pruned and non-pruned models and apply the t-test to determine whether the means of the samples differ significantly. At all levels of pruning, some classes are impacted far more than others
(classes that are statistically significant indicated by pink vs. the classes in grey where the relative change in performance is not statistically significant).
We plot both the absolute % change in class recall (grey and pink bars) and
the normalized accuracy relative to change in overall top-1 accuracy caused by pruning (grey and green markers).
Go ahead and click the buttons below to see the classes impacted by pruning.
The directionality and magnitude of the impact of pruning is nuanced and surprising. Our results show that certain classes are relatively robust to the overall degradation experienced
by the model whereas others degrade in performance far more than the model itself. This amounts to
selective brain damage with performance on certain classes evidencing far more sensitivity
to the removal of model capacity.
The classes that experience a significant relative decrease in accuracy are fewer at every level than those that recieve a relative boost, however the magnitude of class decreases is larger
than the gains (which pulls overall accuracy downwards).
This tells us that the loss in generalization caused by pruning is far more concentrated
than the relative gains, with fewer classes bearing
the brunt of the degradation caused by weight removal.
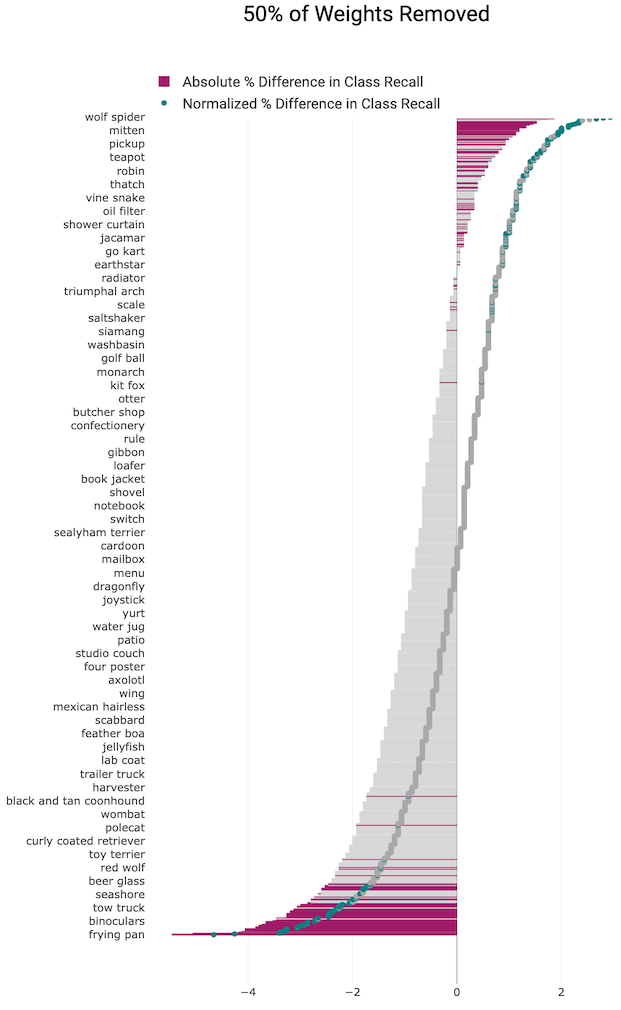
At higher levels of pruning, more classes are impacted and the absolute % difference widens between the classes most and least impacted. Most real world applications of pruning tend to prune above 50% in order to gain the returns in memory and efficiency.
When 90% of the weights are removed, the relative change to 582 out
of 1000 ImageNet classes is statistically significant.
What does this mean for the use of pruned models?
Pruned models are widely used by many real world machine learning applications. Many of the algorithms on your phone are likely pruned or compressed in some way.
Our results are surprising and suggest that
a reliance on top-line metrics such as top-1 or
top-5 test-set accuracy hides
critical details in the ways that pruning
impacts model generalization.
However, our methodology offers one way for humans to better understand
the trade-offs incurred by pruning and gain intuition about what classes
benefit the most from additional capacity. We believe this type of tooling is a valuable first step to help human experts understand the trade-offs incurred by pruning and surface challenging examples for human judgement.
We welcome additional discussion and code contributions on the topic of this work. A comprehensive introduction of the methodology,
experiment framework and results can be found in our paper and open source code.
There is substantial ground we were not able to address within the scope of this work, and underserved areas worthy of
future consideration include evaluating the impact of pruning on additional domains such as language and audio, a consideration of
different architectures and a comparison of the relative trade-offs incurred by pruning methods with other popular compression techniques such as quantization.
Visiting the NeurIPS Google Booth? Take a look at our demo slides here.
Acknowledgments
A special thank you is due to James Wexler, Keren Gu-Lemberg and Prajit Ramachandran for some helpful suggestions about how to visualize and communicate our results in an interactive format.
This article was in part prepared using the Google AI Pair template and style guide.
The citation management for this article uses the template v1 of the Distill style script.
We thank the generosity of our peers and colleagues for valuable feedback on earlier versions of this work. In particular, we would like to acknowledge the valuable input of Jonas Kemp, Simon Kornblith, Julius Adebayo, Dumitru Erhan, Hugo Larochelle,
Nicolas Papernot, Catherine Olsson, Cliff Young, Martin Wattenberg,
Utku Evci, James Wexler, Trevor Gale, Melissa Fabros,
Prajit Ramachandran, Pieter Kindermans, Moustapha Cisse, Erich Elsen and Nyalleng Moorosi.
We thank the institutional support and encouragement of Dan Nanas,
Rita Ruiz, Sally Jesmonth and Alexander Popper.
Citation
@article{hooker2019selective,
title={Selective Brain Damage: Measuring the Disparate Impact of Model Pruning},
author={Sara Hooker and Aaron Courville and Yann Dauphin and Andrea Frome},
year={2019},
url={https://arxiv.org/abs/1911.05248},
eprint={1911.05248},
archivePrefix={arXiv},
primaryClass={cs.LG}
}